|
|
|
Vorab: BegriffeIn der LAPIS-Dokumentation werden für die bekannten Datenbankobjekte andere Begriffe verwendet:
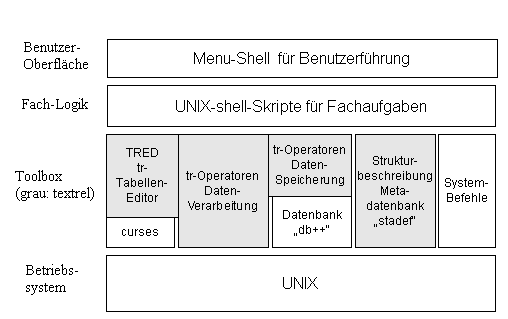
Systemarchitektur:LAPIS besitzt eine geschichtete Architektur (Bereiche anklicken!):
Das textrel-SystemKern der internen Datenverarbeitung ist das textrel-Format (Text-Relationen). Es handelt sich dabei um ein ASCII-Format zur Darstellung von relationalen Tabellendaten. In der ersten Zeile werden Spaltennamen und Datentypen vereinbart, dann folgen zeilenweise die Dateninhalte. Das textrel-Format ist aber in einem wichtigen Punkt gegenüber der üblichen Übertragung von Tabellen erweitert: Pro Datei oder Stream sind mehrere Tabellen mit unterschiedlicher Spalten erlaubt (ungefähr analog zu einer Excel-Datei mit verschiedenen Arbeitsblättern). Alle Tabellen in einer Datei müssen aber einen gemeinsamen Satz von Schlüsselspalten enthalten, während reine Datenspalten variabel sind. Das erlaubt es, heterogene Daten einheitlich zu übertragen und zu verarbeiten. Alle gängigen relationalen Operationen (filtern, join, sortieren) können auf dieses erweiterte Format angewendet werden, die Ergebnisse sind immer wieder Multi-Tabellen. Abläufe, die in SQL mit einem einzigen komplexen SELECT -Statement formuliert werden, sind im textrel-System durch eine Abfolge von tr-Operator-Programmen realisiert, die jeweils über die Kommandozeile gesteuert werden, und tr-Dateien über stdin und stdout weiterleiten. Einige Operatoren splitten auch den Input in zwei Ausgaben auf (z.B. trcheck). Arithmetik mit begrenzter StellenanzahlEiner der Datentypen des textrel-Systems ist ein numerischer Datentyp, der Fliesskomma -Zahlen mit bekannter, begrenzter Genauigkeit verwaltet. Darin werden chemische Anlyseergebnisse mit bekannter Genauigkeit gespeichert.
Der Datentyp ist kompatibel zum C-Datentyp double, die Zahl der gültigen Binärstellen wird
in den am wenigsten signifikanten Bits der IEEEE-Darstellung kodiert. Sonderformen der
mathematische Operatoren verrechnen diese Bits dann mit, so dass im Laufe von
Kettenrechnungen die Genauigkeit immer weiter abnimmt. Das Datenbank-RDBMS db++Zur eigentliche Speicherung der Datenbestände wird das UNIX-RDBMS "db++" von concept asa, Frankfurt, verwendet. Diese Datenbank wird im Wesentlichen über eine interne API -Schnittstelle angesteuert, dabei handelte es sich um eine Bibliothek von C-Funktionen. db++ verfügt nciht über SQL als Abfragesprache, sondern über ein eigene kompakte Operator-Syntax. Dies hat die Entwicklung des textrel-Systems mit geprägt. tr-Operatoren zur Daten-Speicherungdb++ wird von fünf Programmen mit tr-Interface angesteuert: NEW, EXTRACT, RELINK, MAKERELS und FORGET. Diese führten die grundlegenden Operationen auf dem LAPIS -Datenmodell durch: Daten einfügen, abfragen, Datensätze umhängen, Tabellenpflege und Datenlöschung. tr-Operatoren zur DatenverarbeitungAlle möglichen atomaren Operationen auf tr-Dateien werden von folgenden Operatoren ausgeführt (siehe auch das Referenz-Handbuch). Falls möglich, wurde in Klammen das entsprechende SQL-Schlüsselwort angegeben.
Der Editor tredtred- ist ein full-screen Tabelleneditor, mit dem tr-Dateien editiert werden können. Er umfasst viele Sonderfunktionen, und wird innerhalb des tr-Systems als flexible Dateneingabemaske verwendet, da gezielt auszufüllende Tabellenspalten und - zeilen vorgegebnen werden können. Auch zum Eingeben von Suchbedingungen wird er verwendet. Besonderheiten sind:
Tred verwendet die UNIX-Bibliothek curses, um verschiedene ASCII-Terminals richtig ansteuern zu können.
Die Metadatenbank STADEFSTADEF steht für Stationen-Definition. LAPIS organisiert den Analysebetrieb im Labor abstrakt als Proben, die nacheinander verschiedene Stationen durchlaufen und an jeder Station eine von mehreren Behandlungen erfahren. Pro Behandlung fällt ein individuell strukturierter Datensatz an. Die speicherbaren Felder der verschiedenen Behandlungen werden in feste Kategorien wie Zeit, Bearbeiter, Masszahl, Methode,... eingeteilt. Die Organisation eines konkreten Labors wird im stadef-Konfigurationsfile StationenDef eingetragen. Das Tool stationchk verifiziert die angegebene Laborbeschreibung. Mittels des front-ends defs können gezielt Informationen aus stadef abgefragt werden. Beispiel: Was sind alle Methoden-Felder der Stationen bis Aufschluss, und was wird in Aufschluss alles gemessen?. Das Ergebnis bilden Feldlisten, aus denen dann zum Beispiel tred-Maskendateien erstellt werden. Diese Feldlisten werden dann als Argumente beim Aufruf der tr-Operatoren eingesetzt. Fachlogik als sh-ScripteDie genannten Tools und tr-Operatoren werden benutzt um fachliche Abläufe in Form von UNIX-shell.Scripten zu programmieren. Dies hat den Vorteil, dass schnell und flexibel auf neue oder geänderte Anforderungen reagiert werden kann. Der Ansatz für die Architektur war:
Die Fachlogik von LAPIS besteht aus ca. 60 Script-Dateien, kleinere sh-Code-Blöcke sind direkt als Aktionen in die Menü-Steuerdateien eingebaut. Das Menü-SystemFür LAPIS wurde eine menügesteuerte Benutzeroberfläche msh entwickelt, das look and feel wird im Anwenderhandbuch gezeigt. Mit diesem Menüsystem wird die Arbeit mit den verschiedenen Fachmodulen organisiert. msh wurde LAPIS-unabhängig geschrieben. Es liest Menübeschreibungen aus speziellen Menu-Dateien und präsentiert diese dann dem User zur Navigation. Der Menufile definiert Menus, ein Menu besteht aus mehreren Tops. Die Aktion bei der Auswahl eines Tops ist ebenfalls angegeben, es kann die Ausführung von sh-Code oder der Aufruf eines Untermenüs sein. Weitere Features sind:
|
| [LAPIS] [Geschichte] [Architektur] |